Week 4 Homework
Bringing it all together on the university data
1 Using quarto-live documents
Within this document are blocks of R code.
- Edit the code that is shown in the box. Click on the
Run Codebutton. - Make further edits and re-run that code. You can do this as often as you’d like.
- Click the
Start Overbutton to bring back the original code if you’d like.
2 Instructions for this homework
- This is a long homework, and you shouldn’t think that you can do it all at once, or even before the class is over. It is meant to be something that you can use to remind yourself about all that we learned in this class. So come back to it periodically and try to answer a question that you haven’t attempted before or that it’s been a while since you’ve done it.
- You should definitely try this for the first time within this Web page so that you can access the hints.
- However, you should also definitely do this eventually within
RStudioso that you can see how the whole “put the output in the workbook” process works.
3 Preliminaries
3.1 Setup
We have loaded both the tidyverse and tidylog packages in the background. If you are working in RStudio, then run the following code at the Console:
library(tidyverse)
library(openxlsx2)
library(kableExtra)3.2 Load the data
We are now going to load the raw data from the CSV files. If you are working in RStudio, then execute the following code at the Console:
source("source/read_in_university_data.R")If you are working in this web page, then read in the data and display it by running the following code. Note that this skips the validity checking that happens in the source file above; however, this is a lot of calculations and takes time over this Web connection, so we’re trying to minimize this for you.
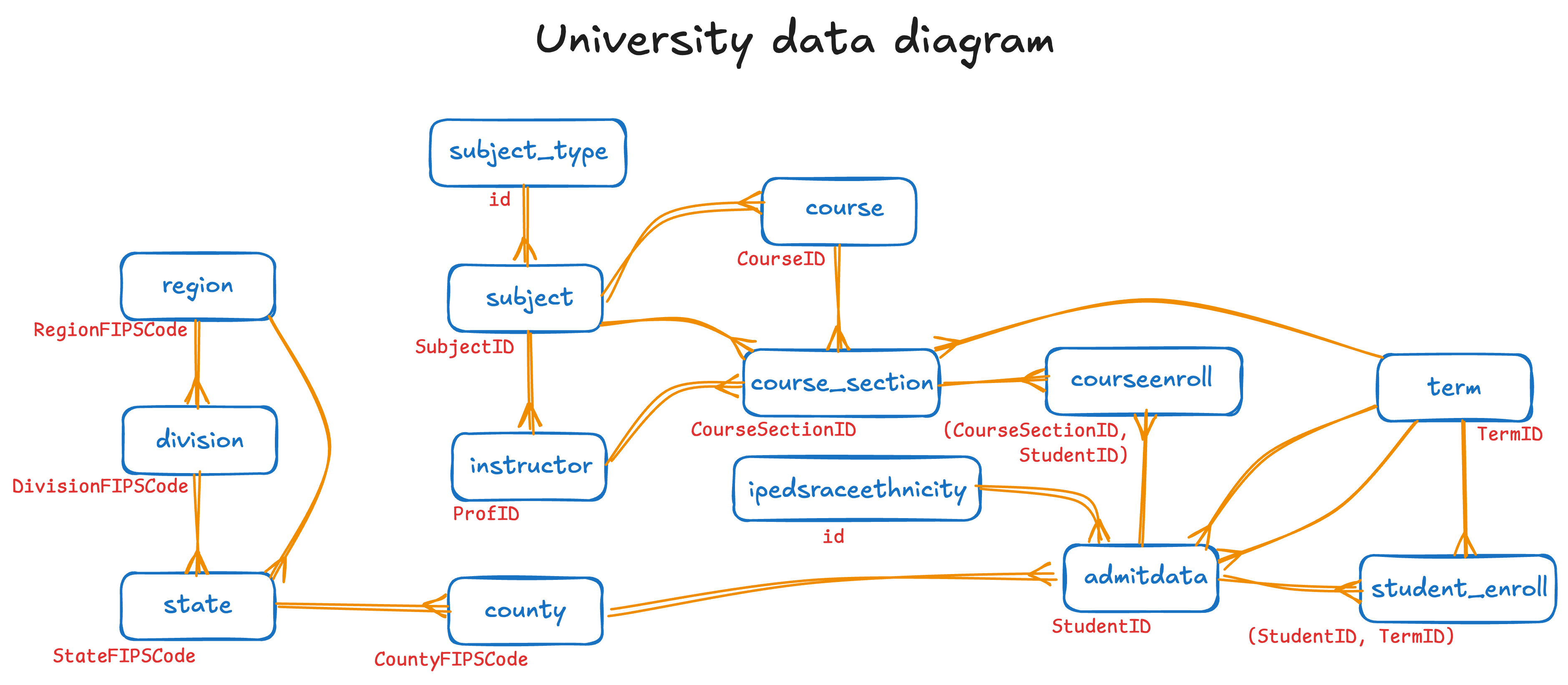
3.3 ER diagram
This is the entity-relationship (ER) diagram for this data set. Let me know if we have missed a relationship or if we could otherwise make this diagram more useful.
We’ll provide this code chunk box that you can use to explore the data as you would like (without having to re-load the data as you would in the above box). We’ll start you out with this code that lists all of the data frames in your global environment.
What to do if all goes wrong?
If you do something on this page and somehow mess up some data frame, then just run the above code block again. It will reload the data. You can then go back to where you were working.
4 Process that you should follow
For each question in this homework (as for each query you ever construct), you should follow this general process (though we must emphasize that this will be iterative, and you will continually cycle back through this process as you refine your query):
- Determine what information you want to display. This will generally rely on your knowleedge of the specific columns in the available data sets. We’ll refer to this as your target data.
- Find the data frames that hold that information.
- If you have found more than one data frame:
- Find all the data sets in the ER diagram
- Determine the path through the ER diagram that you will take to connect all the appropriate data sets
- Find your base data frame that will serve as the left-most data frame
- Join the tables together
- Filter to include the rows you need
- Select the columns you need and rename them if desired
- Add groups and calculations (or sort if no groups are needed)
- At this point, and only at this point, build the
forloops that you need to put the results in different reports or worksheets
In our hints, we will generally proceed in that order — target, data frames, joins, filters, selects, groups, loops.
5 Questions
We have included a link to the ER diagram (Figure 1) at the end of each question because we know how much you will need to refer back to it. (You might also consider printing it out.)
Before you start working on the questions, you need to execute the following. Similarly, if you are working in a script in RStudio, then you should insert this code after you have read in all of the data from the CSV files.
Since you will, almost assuredly, work on these questions over a period of time, even if you work in this Web page (as opposed to RStudio), we encourage you to build up a working R script to capture your answers to each question (and the preliminary setup and reading in of the data). That way, when you are done, you can execute the whole script and enjoy the satisfaction of completing a significant project — and running it again and again with zero additional effort!
Question 1: List instructors
Display the Subject type & name, and Instructor name. List the subjects alphabetically by type, and the instructors alphabetically within subject. (Figure 1)
As a reminder, this is the order to proceed: target, data frames, joins, filters, selects, groups, loops. We’ll get you started.
- Targets
- For now, we’ll start with Subject Type, Subject Name, and Instructor Name.
- Data frames
-
It looks like, from scanning the ER diagram and the output of the query just below it that lists the column information, we need the data frames
instructor,subject, andsubject_type. - Joins
- This, and the remaining, we leave for you.
We’ll start you off by listing the column names for these three data frames. Until you finish this entire question, we recommend that you leave these three short queries in the code box while you add your answer below it.
So, your first step (and the topic of your first hint) will be to join these data frames together. You, of course, must determine the left-most data frame before you can construct this portion of the query.
A bit of help
Since we want to list all the instructors and not leave any out, it makes sense to start with the instructor data frame. Using the names() output from above, we determine the primary keys and foreign keys to join together.
Next up: Determine filter() and select(). What information do we want to include?
A bit of help
This is where we refer back to our targets and put them in a select() statement.
Next up (and the solution): Do we need to sort?
Solution
The instructions specified to list the subjects and professors alphabetically. We added the sort by subject type but you could certainly leave it out.
Question 2: List courses
Display courses by subject by type. Include information about whether or not they are general ed or major courses. (Figure 1)
A bit of help
The targets for this query include the following:
- subject type
- subject name
- course ID
- course name
- audience
A bit of help
We can find the targets in the following data frames:
- course
- subject
- subject type
A bit of help
joins
Next up: What rows do we want to filter and columns do we want to select?
A bit of help
The question does not refer to any restriction of data to include; thus, we do not need a filter() in this query.
As for select(), we just refer back to the targets and see that all of the information is available directly as a column.
Next up (and the solution): Do we need to sort?
Solution
The question refers to displaying courses by subject by type; thus we include that specification in the arrange() statement at the very end.
Question 3: List courses by subject
Output into a workbook a list of courses (with their credits, audience, and maximum enrollment) by subject. Put each course listing on a separate worksheet. (Figure 1)
A bit of help
We need to include the following as targets:
- subject ID (to define the worksheet pages)
- course ID
- credits
- audience
- maximum enrollment
Next up: What data frames must be included?
A bit of help
The course data frame is all that we need; no joins are required.
Next up: What do we need to filter to include? Use "FINAN" as the sample value for my_subject in the construction of your filter() statement.
A bit of help
Since we know that we are going to integrate this into a for statement, we are going to build the query as if it is already within that loop.
Next up: What columns do we want to select?
A bit of help
As always, in adding a select() statement, look at your list of targets. Note that each of this information is already in a column in the data frame. We simply add these to the select() statement.
Next up: Do we need to sort?
A bit of help
We are already separating the reports by subject, so all that remains for sorting is by Course (which is how we have renamed CourseID).
Next up: Define the basic for structure. Put it after the code above (i.e., don’t delete it!).
A bit of help
Here we build the basic structure of a for loop so that we can test that we have it correct. Only after we have it working correctly (with the following) will be go ahead and attempt to integrate our existing query into it.
Next up: Integrate the query into the for loop.
Solution
This step is not much more than just copy-and-paste…but it’s that easy because we already did the difficult work of writing the query and building the standard for loop.
Question 4: List counties
Display the Region name, Division name, State name, and County name and the relative size of the county’s labor force (that is, the percentage of its state’s labor force), in descending order of its relative percentage size. This will show which counties in the US make up the largest portion of its state’s labor force. (Figure 1)
Next up: The first thing to do, as always, is determine the targets. For this query, this step is a bit more challenging. Think carefully.
A bit of help
The targets here are a bit different than before. Certainly we have the information that is already in the data set:
- region name
- division name
- state name
- county name
But then we also have the following:
- county’s relative size of the labor force, calculated from
- county labor force
- state labor force
Next up: What data frames do we need?
A bit of help
The data frames we need for this query are as follows:
- region
- division
- state
- county
Next up: Join the data frames together.
A bit of help
These are fairly easy joins to make…except for the one to region.
If you’re having trouble with this one, build this step one join at a time. Look at the results. Then build the next join. When you get to the result of the second join, you will notice that there are two RegionFIPSCode columns resulting from the second query since each of those data frames has a RegionFIPSCode column in it.
To address this (i.e., a data frame cannot have two columns with the same name), R changes the name of the column from the left data table to RegionFIPSCode.x and the column from the right data table to RegionFIPSCode.y. It turns out that they both have the same value in this case. (Why?)
Thus, when you perform the last join to region, you need to choose one or the other to join with RegionFIPSCode from the region data frame.
Next up: Apply the appropriate filter() and select(). In this step we also add one other statement that we haven’t had to use thus far.
A bit of help
We do not need to restrict the data in any way for this question; thus, we do not include a filter() stastement here.
As for select(), we need to include the six columns shown below. (Note the same issue with LaborForce2021; in this case, one contains the county’s labor force and the other contains the state’s labor force. Thus, we keep both and rename them.)
We also add a mutate() statement since we have to calculate the relative size column.
Next up (and the solution): Do we need to sort anything?
Solution
We want all of the counties and their data to be sorted in descending order by the relative size. Thus, we add an arrange() at the very end.
Question 5: Number of students by section
For each section of each course in Fall 2018, calculate the number of students taking that section. Sort by class size within subject. Also show the professor’s name who teaches each section.(Figure 1)
First up: What targets do we have?
A bit of help
We have a bit more complicated list of targets here.
Start with the ones that we want to show:
- subject ID
- course ID
- course name (or title)
- professor’s name
Now, while filtering, selecting, calculating, and arranging, we also need to have IDs for any associated target (because multiple things can have the same name but actually be different):
- course section ID
- professor ID
We will want to select these at the beginning but then get rid of them when creating our report.
Finally, we also have the following that we have to calculate:
- count of students taking the section of the course
Next up: What data frames do we need to include?
A bit of help
We need to include the following data frames so that we can access our targets:
course_enrollcourse_sectionterm(since we are usingfilter()on columns in this data frame)course
The left most data frame should be course_enroll because we want to count all enrollments in a course/section.
Next up: Join these tables together.
A bit of help
These joins are quite straight-forward since the column name is shared between each joined data frame.
Next up: What do we need to filter() to include?
A bit of help
This is a fairly easy filter()…except you might notice that we put it in the middle of the query. Our general strategy is to include a filter as early in the overall query as possible since it can greatly reduce the volume of data that is being manipulated. This is definitely the case here since we are only looking at one semester out of the 28 that are in the data set.
Next up: What columns do we need to select()?
A bit of help
The only complication on the select() is the SubjectID since there were two such columns, one in course and one in instructor.
Further, you might notice that we do not select either Season or Calendar Year as we assume that, since the filter() ensures that each only has one value, we do not need to display those columns.
Next up: What columns do we need to group_by() and then summarize()?
A bit of help
We now want to calculate the number of students in a specific section of a specific course taught by a specific professor (of course, it’s the same one-and-only-one professor for any one section). We go ahead and rename the new column as count.
Next up (and the solution): Do we need to sort?
Solution
This last step is quite tricky in the last three lines.
Unless you include the ungroup(), R/tidyverse keeps adding back the CourseSectionID and the ProfID so that it can maintain the groups. We do not need to maintain them any more, so we can go ahead and apply the ungroup(). Having done so, our select() works correctly, and the arrange() then sorts by department with sections in descending order by their enrollment within the department.
Question 6: List courses in a subject by popularity
Output into a workbook, a count of students by course (not course section) in each subject for Spring 2021. Sort in descending order by count within the subject. Create a separate worksheet for each subject. (Figure 1)
Next up: What targets do you have for this query?
A bit of help
The targets for this query are the following:
- subject ID (used to define a worksheet)
- course ID
- “# enrolled” (calculated)
Next up: What data frames do we need?
A bit of help
The data frames we need for this query are as follows:
course_enrollcourse_sectcioncourseterm(for filtering)
Next up: Join those data frames together.
A bit of help
This is a fairly straight-forward join. We also include the filtering on my_subject since we know that we’re building this for a for loop later on in the process.
Next up: What rows do we need to filter to include?
A bit of help
Here we apply the filter() to reduce the data dramatically to just one semester.
Next up: What columns do we want to select?
A bit of help
We only need to select one column (CourseID) since we are filtering on SubjectID already.
Next up: What columns do we need to group_by() and summarize()?
A bit of help
Since we are calculating by course and not section within each department, we simply group by CourseID. The calculation is then just the number of rows in each group…or n(). To clarify what the n represents, we rename the column.
Next up: Do we need to sort?
A bit of help
We want to show the counts in descending order by enrollment within the department.
Next up: Build the basic for loop structure. Do not delete your existing query. You will need it in the next step. Put the for loop after your existing query.
A bit of help
Here we add our usual for loop structure after the query.
Next up: Integrate the two so that the query is within the for loop.
Solution
Finally, we integrate the query into the for loop.
Question 7: List low enrolled courses at the university
Output into a workbook, a count of students by course (not course section) for the whole university in Spring 2021. Sort in ascending order by count within the university. List just the courses with counts < 40. (Figure 1)
A bit of help
The targets for this query are as follows:
- subject ID
- course ID
- Number enrolled in the course
Next up: What data frames do we need?
A bit of help
The data frames that we need for this query are as follows:
course_enrollcourse_sectioncourseterm(for filtering)
Next up: Join the data frames together.
A bit of help
When the column names match in a join, it makes it much easier to specify. We started with course_enroll on the far left because we want to count everyone who is enrolled.
Next up: What rows do you need to filter() to include?
A bit of help
We need to filter on the name of the semester. Since the name is in the term data frame, we put the filter() after that join. Notice that we moved the left_join() for term to just after the left_join() for course_section. That is where the TermID column is located that is used for the term left_join(). As we pointed out previously, when filtering down to just one semester, this reduces the amount of data radically; thus, we want to move the filter() as early in the process as possible.
Next up: What columns do you need to select()?
A bit of help
When we listed our targets previously, we established that we need SubjectID and CourseID. We do not have a count yet because we have not calculated it. That target will have to wait.
Next up: What columns do you need to group_by() and summarize()? (I also add a filter() at the end of this next step.)
A bit of help
What we have after the previous stage — always, always, always, you need to assess this very question: “What do we have here?” — is a separate line for every student enrolled in every class in Spring 2021, and all the information we need to identify that section and class.
Thus, if we group_by() for SubjectID and CourseID and then summarize() to calculate n(), then each n will show a count of the number of students in each course by subject.
We add the filter() at the very end because we are only interested in classes that have fewer than 25 students in them.
Next up: Do we need to sort anything? And put this single data table into a worksheet.
Solution
We have two tasks here.
- Sort appropriately
-
We want to see the list of courses by subject by course; thus, we put an
arrange()at the end of theR/tidyversequery. - Put into a worksheet
-
So far, we have only put a data frame into a worksheet when it’s been inside a
forloop. This time, we simply insert the three needed commands after the data frame has been created.
Question 8: Graduated students per major over the years
What is the number of graduated students per declared major per admitted school year for all years in the data? (Figure 1)
A useful fact to know is that any student who has not graduated has a 0 in the GraduationTerm column of admit_data. If the student has graduated, then that column contains the term ID.
A bit of help
We have an interesting set of targets for this query:
- declared major
- school year when graduated (not calendar year, and not term ID, but school year)
- number of students who graduated with this major in that year
Since we have 12 majors and at least that many years, we need to think about how we’re going to present that information. It will probably make sense to pivot it at some point (near the end, we’re guessing) to get it in a form that someone can more easily interpret.
Next up: What data frames do we need?
A bit of help
We only need two data frames for this query: admit_data and term.
Next up: Join the tables together.
A bit of help
This join is a bit more complicated than usual. We are interested in when the student was admitted, so that is the AdmitTerm column. This has a term ID in it (a foreign key to term), so it should be connected to TermID. Having done this, we now have access to the admit Season, admit CalendarYear, and admit SchoolYear of each student.
Next up: What rows do you want to filter() to include?
A bit of help
We are only interested in students who are graduated, so we want to filter() to include those rows for which GraduationTerm has a value greater than 0 — that is, has been assigned a specific term during which they graduated.
Next up: What columns do you want to select()?
A bit of help
We do not need to select() any columns here because we are going to use group_by() for a calculation (in the next step, actually). We could, if we wanted to reduce the amount of data being moved around in the query, use select() on DeclaredMajor and (admitted) SchoolYear; however, we have chosen not to do this.
Next up: What columns do you want to group_by() and summarize()?
A bit of help
The question specifies that we’re interested in counts by declared major and admitted school year. Thus, we use a group_by() on those columns and then n() to count the number of students with each major and admitted school year.
The result of this query — look at it! — is a typical long data set. For analysis, this is awesome; for showing it to people…not so good. It’s just too long to easily scan.
Thus, you can just feel that we’re going to do a pivot, can’t you?
Next up: What remaining step do we need to take to make it easier to present this information?
Solution
We want to pivot this long data to wide data and put the admitted school years across the top with table values coming from our previously calculated Num column. Since we also grouped on declared major at the same time, these will be the values down the left side of the table.
Just as a reminder, if you wanted to put these results in a worksheet, then you should add the following lines to the above.
#' Save for later output into an Excel Workbook
wb <- add_ws(wb,
"GraduatesPerMajorPerAdmitYear",
"Graduates per major per admit year")
wb <- add_data(wb, graduatesPerMajorPerAdmitYear)
wb <- set_ws_formatting(wb, graduatesPerMajorPerAdmitYear)Question 9: Average grades per department over the years
For courses offered between Fall 2015-Spring 2022 (inclusive; that is, from term 113 to 126), what is the average grade per department offering it (not per section)? List the results in descending order by the average. (Figure 1)
A bit of help
Our targets for this are a bit of a challenge to figure out. Certainly, we want to have the SubjectID for the course being taken as well as the term number for the course. And we are also looking for information related to grades — specifically, the average grade of the student enrolled in a section of a class. We are not interested in displaying course information or student information. So that leaves us with the following targets:
- subject ID for the course being offered
- term ID for the course
- average grade per course
Next up: What data frames do we need?
A bit of help
All that we need are course_enroll and course_section. We do not need to include term because we already have determined that the TermID is 113--126.
Next up: Join the data frames together.
A bit of help
We should be familiar with doing this join by this time.
Next up: What rows do we want to filter() to include?
A bit of help
The question specified at the very beginning that the TermID must be in the range 113--126 so we use this and (&) filter to do so.
Next up: What columns do we want to select?
A bit of help
Again, at this point we do not need to select() anything in particular because we are going to calculate some values with group_by() and summarize(), and this always removes most columns from the data frame.
Next up: What columns do we want to group_by() and summarize()?
A bit of help
We are interested in average grades per department, so that means that we need to group_by() the SubjectID and the calculate the mean() for GradePoints.
Next up: Do we need to sort anything?
Solution
The question specifies that we want to sort in descending order by average grade, so we add the appropriate arrange() at the end of the R/tidyverse query.
Question 10: Recent student load by professor
For each department, calculate the number of students taught by each professor per audience type (and in total) over the last six terms. Be sure to print the professor’s name. The results should be sorted descending by total number of students taught. Put the results for each department in a separate worksheet. (Figure 1)
A bit of help
This is quite a complicated question and, as such, requires a bit of thinking to even determine the targets:
- department ID and name
- professor ID and name
- course ID and audience
- term ID for the course
- count of the students in a course section (as represented by rows) and per audience type and total number of students.
It’s not quite clear to us right now exactly how all of these counts will come together. We’ll try to determine it as the query evolves.
We will also have to have course section information along the way since professors teach students who are in course sections. We do not need student information per se (other than the count of those students).
A bit of help
The data frames that we need are somewhat familiar:
coursecourse_sectioncourse_enrollinstructor
Next up: Join the data frames together.
A bit of help
The left_join() statements needed to join these data frames together are easy to specify since the column names are shared by each pair.
Since we are prepping for a for loop, we are setting up for it by choosing a specific subject ("FINAN" in this case) and putting the filter() on it as soon as we can within the query.
Next up: What rows do we want to filter() to include?
A bit of help
The question states that we’re interested in courses taught over the last six terms. We want this query to be useful if we run it again in the future. One way to do this is to calculate the current maximum term ID, and then use that number as the basis for determining what “over the last six semesters” actually means (in the script).
Thus, on the second line below we calculate max_term, and then we include a filter() on line 6. This early filter helps minimize the amount of data that we’re manipulating in the query — especially valuable since course_enroll is such a large data frame.
Next up: What columns do we want to group_by() and `summarize()?
A bit of help
We are interested in calculating by professor by audience type (by subject, but we’re handling this with a separate worksheet for each). Thus, our group_by() is over ProfID and Audience.
Note, however, that we put both the group_by() and summarize() before the left_join() for instructor. Why? ProfID is in course_section and Audience is in course, so why did we not put these two commands after the first left_join()? Because we want to count the number of students enrolled in a specific section of a specific course, and this information is in course_enroll. Thus, we can put these two commands as early as where we have put it.
Note that if we put these two statements after the last left_join(), then we would have had to group_by() ProfID, ProfName, and Audience! Why? Because the question states that we need to display the professor’s name and, if we had not grouped by the professor’s name then that information would not have been available later in the query.
Next up: What columns do we want to select?
A bit of help
Below, you can see that we include four columns in the select(). Note that if we do not have two professors with the same name in the same department across the whole university, then we could have not included the ProfID. This is one of those “it’s better to be safe than sorry” situations.
Next up: How should we pivot in order to make the information easier to understand?
A bit of help
For each professor, we want to have the counts for GENED and MAJOR on the same row, so that means that we pivot on Audience and put the Num column in the body of the table.
Once we have the GENED and MAJOR totals on the same line for each professor, it makes it easy to use mutate() to calculate the TotalStudents column.
Next up: Do we need to sort anything?
A bit of help
The question states that we’re interested in sorting in descending order by total number of students taught. That’s easy to accomplish with the arrange() that we put at the end of the query.
Next up: Build the for loop structure.
A bit of help
We have put our generic for loop below the query with a bit of specificity to create the worksheet name and the report name.
Next up: Integrate the two.
Solution
Now it’s really just a matter of a bit of copy-and-paste to bring the two together.
At the very end of your R script in RStudio, add the following line so that it will all be transferred to a workbook.
save_wb(wb, "output/output.xlsx")Congratulations!